Отказоустойчивый кластер (кластер высокой доступности, high availability cluster, HA-кластер) — группа серверов, гарантирующая минимальное время простоя виртуальных машин (ВМ). Отказоустойчивые кластеры используют, например, для поддержки серверов баз данных, хранения важной информации, работы бизнес-приложений. В случае, если один из серверов (узлов) кластера потерял связь с другими узлами или подключённым хранилищем, VMmanager запустит процесс аварийного восстановления — релокации ВМ:
- перенесёт ВМ с отказавшего узла кластера на рабочие;
- остановит ВМ на отказавшем узле кластера;
- изолирует отказавший узел кластера.
Процесс релокации проходит автоматически без участия администратора.
Требования к отказоустойчивому кластеру
Вы можете создать отказоустойчивый кластер при следующих условиях:
- тип виртуализации — KVM;
- тип сетевых настроек — "Коммутация";
-
типы хранилищ:
- для версии Hosting — SAN;
-
для версии Infrastructure — SAN и NAS в любых сочетаниях;
К отказоустойчивому кластеру не должны быть подключены хранилища других типов.
- ОС на узлах кластера — AlmaLinux 8 или Astra Linux Special Edition 1.7.4, 1.8.1;
- количество узлов — от 3 до 24 (указано максимальное количество узлов, с которым конфигурация была протестирована);
- системное время на всех узлах синхронизировано. Для синхронизации времени на узлах с ОС AlmaLinux используйте ПО chrony, на узлах с ОС Astra Linux — ПО ntp;
- платформа не запущена на ВМ внутри одного из своих кластеров.
Рекомендации по использованию
- Не рекомендуется добавлять в кластер проблемные узлы — серверы, которые склонны к аварийным ситуациям из-за проблем с ОС, дисками, сетью и т.д.
- Перед включением отказоустойчивости убедитесь в надёжной работе сетевых хранилищ и каналов связи с ними.
- Не рекомендуется устанавливать коэффициент оверселлинга RAM на узлах более 0,9.
- Установите такой запас свободных ресурсов, который позволил бы в случае аварии одного узла разместить и запустить все ВМ кластера, выбранные для восстановления.
- Используйте отказоустойчивый кластер для тех ВМ, к которым важно восстановить доступ в случае аварии.
При несоблюдении рекомендаций возможны следующие риски:
- увеличение числа отказов;
- нехватка ресурсов;
- сбои в работе ПО, приводящие к остановке и перераспределению ВМ в кластере;
- сбои в перемещении ВМ при аварии узла;
- утрата работоспособности у отдельных ВМ в кластере.
Логика работы
Используемые сервисы
Для управления отказоустойчивым кластером VMmanager использует:
- ПО Corosync с сетевой технологией Kronosnet;
- собственный сервис ha-agent;
- cобственный микросервис hawatch.
Платформа запускает сервис ha-agent на каждом узле кластера. Сервисы ha-agent взаимодействуют между собой с помощью ПО Corosync. Алгоритмы Corosync назначают один из сервисов ha-agent мастером. В дальнейшем платформа взаимодействует только с этим сервисом с помощью hawatch.
Процедура выбора мастера
Выбор мастера происходит в следующих ситуациях:
- при включении системы отказоустойчивости в кластере;
- при выходе из строя действующего мастера;
- при изменении конфигурации HA-кластера;
- при обновлении версии HA-кластера.
Чтобы выбор прошёл успешно, в нём должно участвовать (N/2 + 1) узлов, где N — общее число узлов кластера. Значение (N/2 + 1) нужно округлить до целого числа в меньшую сторону. Например, в кластере с двумя узлами должны участвовать оба узла, в кластере с 17 узлами — 9. Если исправных узлов в кластере меньше, чем необходимо, процедура выбора не начнётся. Если узлов будет больше, чем необходимо, то в выборе примут участие только те узлы, которые были готовы к процедуре раньше. Алгоритмы Corosync гарантируют, что информация о времени готовности узлов к выбору одинакова для всех участников кластера.
При выборе мастера каждый из узлов-выборщиков с помощью специального алгоритма рассчитывает свой приоритет и сообщает его остальным участникам кластера. Мастером назначается узел с самым большим приоритетом. После назначения мастера кластер начнёт работу в режиме отказоустойчивости.
Узлы, которые были не готовы к началу выбора мастера, присоединяются к кластеру после завершения процедуры выбора. При добавлении новых узлов в отказоустойчивый кластер повторный выбор мастера не проводится.
Обычно процедура выбора занимает около 15 секунд.
Статусы узлов кластера
В отказоустойчивом кластере сервисы ha-agent на узлах могут принимать следующие статусы:
- рабочие:
- Мастер-узел — узел в рабочем состоянии и выбран мастером;
- Активен — узел в рабочем состоянии и является участником либо в промежуточном рабочем состоянии (выборы или ожидание обновления);
- Мастер-узел — узел в рабочем состоянии и выбран мастером;
- нерабочие:
- Изоляция по сети — узел недоступен по сети, но у узла есть доступ к хранилищу. Статус устанавливается, если узел недоступен для сервисов ha-agent на других узлах кластера;
- Нет связи с хранилищем — у узла нет доступа к хранилищу, но узел доступен по сети;
- Недоступен — узел недоступен по сети и у него нет доступа к хранилищу. Статус устанавливается, если у платформы нет доступа к узлу;
- Исключен из HA-кластера — узел недоступен по сети, но имеет доступ к хранилищу. ВМ узла временно исключены из кластера, их перенос не выполняется;
- специальные:
- Неизвестный статус — точный статус узла неизвестен. Например, отказоустойчивость находится в процессе включения;
- Проблема с подключением HA — задача включения отказоустойчивости на узле завершилась с ошибкой.
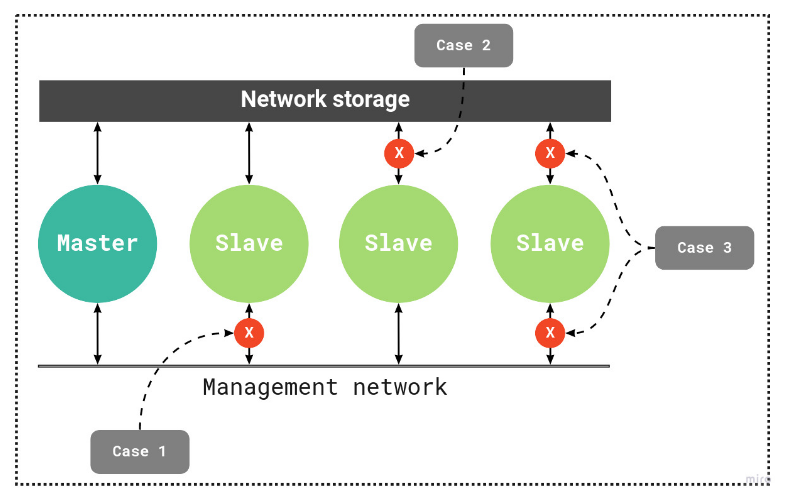
Схема работы HA-кластера
Определение статуса узла
Сервис ha-agent считает узел повреждённым, если узел потерял связь с другими узлами кластера и/или подключённым хранилищем. Проверка связи проводится с помощью алгоритмов Corosync. Дополнительно узлы кластера записывают информацию о своём статусе в файл на сервере хранилища. Обновление статуса происходит один раз в три секунды. Если информация о статусе не обновлена, мастер определит узел как повреждённый.
Среднее время определения нерабочего статуса — от 15 до 60 секунд.
В настройках отказоустойчивости можно указать проверочный IP-адрес. При потере связи с кластером узел проверит доступность этого IP-адреса с помощью утилиты ping:
- если IP-адрес недоступен, узел будет изолирован и запустится процесс релокации ВМ;
- если IP-адрес доступен, узел будет исключён из отказоустойчивого кластера. ВМ на этом узле продолжат работу.
Если узел регулярно теряет связь по сети на срок менее 15 секунд, он получает статус "сеть нестабильна". Процедура релокации в этом случае не проводится.
Процедура аварийного восстановления
Когда узел кластера определяется как отказавший, сервис ha-agent на узле:
- Останавливает все ВМ. Если ВМ не удалось остановить, перезагружает узел.
- Изолирует узел.
- Передаёт информацию о статусе узла мастеру.
Когда мастер получает информацию об отказе узла или самостоятельно определяет узел как отказавший, запускается процедура релокации ВМ. Порядок релокации ВМ зависит от значений приоритетов запуска — чем выше у ВМ значение приоритета, тем раньше она будет перенесена. Процедура релокации запускается только для тех ВМ, которые были выбраны в настройках отказоустойчивости.
После перезагрузки узла его ВМ запустятся, только если узел имеет один из рабочих статусов — "мастер" или "участник" . Запущены будут только ВМ, которые принадлежат этому узлу согласно метаданным кластера. Такой подход позволяет избежать случаев "split brain", когда к одному диску подключаются одновременно две ВМ.
Восстановление ВМ в отказоустойчивом кластере
В настройках отказоустойчивого кластера задаётся список ВМ, подлежащих восстановлению. Сервисы ha-agent отслеживают и поддерживают статусы этих ВМ по метаданным, полученным от платформы.
Например, в настройках платформы у ВМ статус "Активна". Если пользователь выключил эту ВМ средствами гостевой операционной системы, сервис ha-agent восстановит её работу.
Удаление ВМ в отказоустойчивом кластере
Перед удалением виртуальная машина переводится в режим обслуживания. Это позволяет избежать ситуаций, когда сервисы ha-agent выполняют действия с ВМ в процессе её удаления.
Создание отказоустойчивого кластера
Чтобы создать отказоустойчивый кластер:
- Настройте сетевое хранилище. Порядок настройки для SAN см. в статье Предварительная настройка SAN, для NAS — в статье NAS.
- Подключите хранилище к кластеру. Подробнее см. в статье Управление хранилищами кластера.
- Задайте настройки отказоустойчивости. Подробнее см. в статье Настройка отказоустойчивости.
Диагностика
Конфигурационные файлы Сorosync:
- /etc/corosync/corosync.conf — общие настройки;
- /etc/corosync/storage.conf — настройки работы с хранилищем.
Лог-файл сервиса ha-agent — /var/log/ha-agent.log.
Лог-файл микросервиса hawatch — /var/log/hawatch.log.
Связанные статьи:
Статьи из базы знаний: