
Содержание
Мониторинг — это уже давно история не только про физическое оборудование. Виртуализация стала популярным инструментом. Виртуальные сети и серверы дешевле физических, легко масштабируются, позволяют экономить ресурсы компании. Специалисты используют виртуальные машины для любых задач, связанных с доставкой изолированного сервиса. Например, для тестирования кода, графического проектирования, документооборота, разработки сайтов и многих других.
Чтобы построить эффективную систему мониторинга, давайте определимся с типичной инфраструктурой среднего предприятия. Обычно мы имеем:
- один или несколько кластеров из физических серверов,
- гипервизор и ПО на серверах,
- сетевое хранилище,
- несколько сегментов сетей,
- пулы IP-адресов,
- систему разграничения уровней прав и доступов пользователей,
- несколько виртуальных машин с гостевыми ОС.
Для мониторинга столь разных сущностей зачастую приходится использовать многокомпонентные системы. Например, как эта:
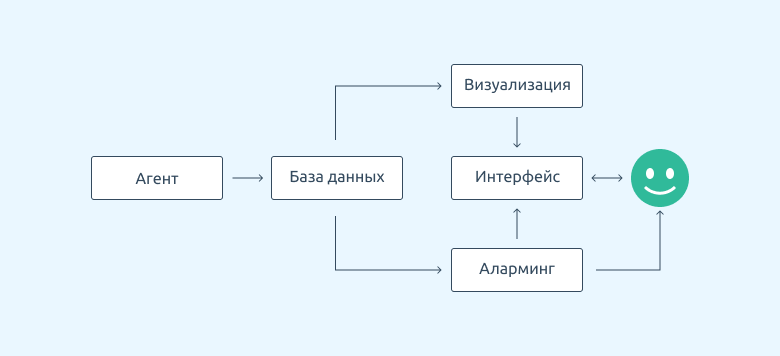
Самостоятельно собрать все компоненты в единую систему и согласовать с архитектурой — непростая задача. И дело не только в технических сложностях. Компании понадобятся специалисты, которые:
- Знают как проводить обслуживание и мониторинг физического оборудования.
- Понимают особенности работы и мониторинга виртуальной инфраструктуры.
- Понимают, как организовать мониторинг сервисов, которые поддерживают эту инфраструктуру.
- Знают, как эти сервисы взаимодействуют между собой.
- Имеют опыт работы с выбранным стеком технологий, либо компания готова вложить время и деньги в обучение специалистов.
- Знают специфику и понимают нюансы бизнес-процессов компании.
- Хорошо понимают IT-архитектуру компании (либо конкретного проекта).
- Знают стратегию развития этого проекта.
Вы уже представляете какого уровня специалисты нужны? Однако IT-системы постоянно растут и требуют все больше ресурсов компании. Скоро может понадобиться второй, потом третий и четвертый сотрудник. А позже обнаружится необходимость в целом отделе из специалистов DevOps, инженеров и аналитиков. И все это для того чтобы эффективно мониторить IT-инфраструктуру.
Но стоит ли изобретать велосипед, когда есть готовое решение из коробки?
Готовая система мониторинга в VMmanager
VMmanager — платформа для построения виртуальной инфраструктуры с готовой системой мониторинга, которая включает в себя набор элементов.
Агент сбора метрик получает данные с виртуальных и физических машин, а затем передает их в сервисы статистики, мониторинга в режиме реального времени, и алармов (для отслеживания пиковых показателей).
Сервис нотификаций отслеживает все события в базе данных платформы: создание, удаление, редактирование данных.
Сервисы самодиагностики платформы отслеживают метрики мастер-узла и события из сервиса нотификаций.
Time-series база данных (Graphite) для хранения статистики.
Быстрые KV-хранилища (consul/redis) для хранения кратковременной информации о нотификациях и алертах.
Визуализация — красивый и удобный интерфейс для мониторинга в режиме реального времени и отображения статистики за выбранный период.
Интерфейс
Список виртуальных машин и узлов
В списке виртуальных машин можно посмотреть информацию о самых важных параметрах ВМ в реальном времени и оперативно оценить их состояние.
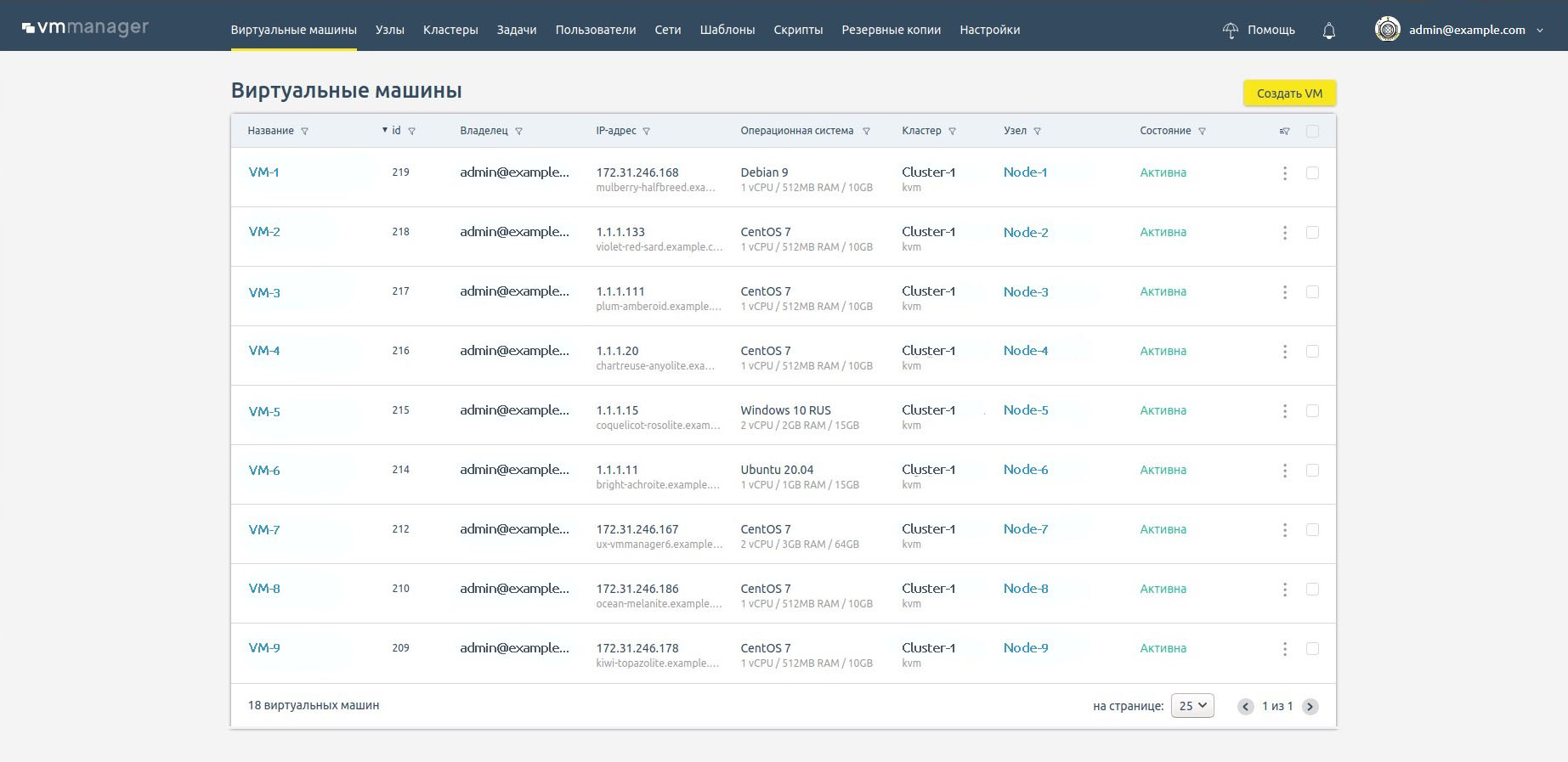
Аналогичная информация есть по физическим серверам в списке узлов.

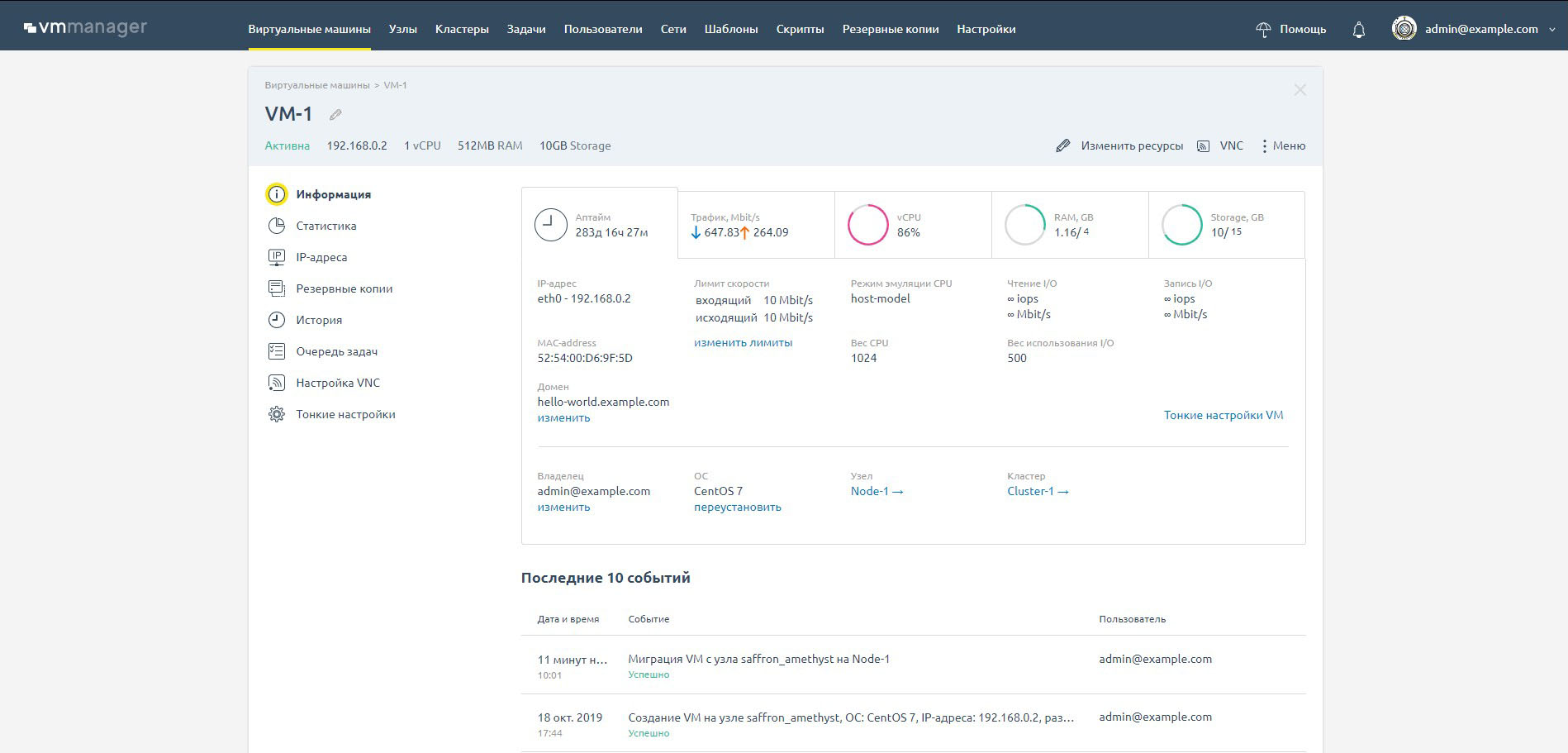
Карточка виртуальной машины
На карточке представлена детальная информация по всем параметрам виртуальной машины. Можно посмотреть статистику за определенный период и проанализировать изменения в инфраструктуре. В карточке можно управлять параметрами виртуальной машины:
- Сетевыми настройками,
- Доменным именем,
- Параметрами VNC-подключения,
- Резервными копиями,
- Тонкими настройками libvirt-домен: вес CPU, IO, ограничения по трафику, режим эмуляции оборудования.
Карточка узла
На карточке узла представлены данные о количестве активных, остановленных, поврежденных виртуальных машин, и прогноз, сколько еще ВМ примерно вместит физический сервер. Это помогает лучше оценивать имеющиеся физические ресурсы и планировать закуп оборудования.
В истории изменений фиксируются данные по всем последним событиям: время их запуска, продолжительность, статус задачи (в очереди, готово, выполняется), и имя пользователя, который их запустил. Можно посмотреть принадлежность сервера к кластеру и гостевые ВМ, которые исполняются на конкретном оборудовании. Всё это помогает обеспечить прозрачность бизнес-процессов компании.

Дашборд
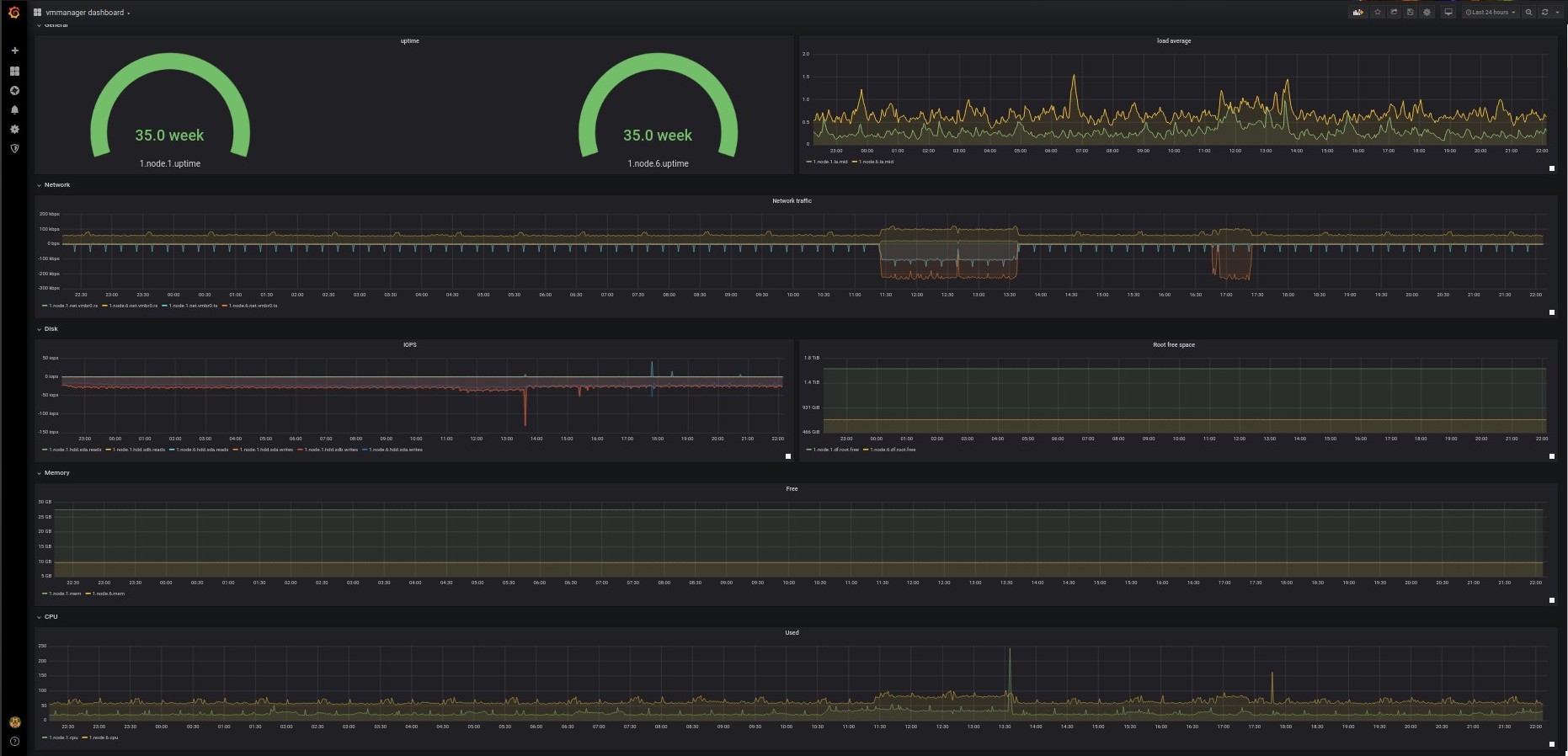
На дашборде собраны основные показатели системы. Его можно вывести на отдельный монитор, чтобы иметь возможность быстро оценивать текущее состояние инфраструктуры и оперативно реагировать на инциденты.
Здесь представлены и новые параметры. Например, виджет самодиагностики платформы, статистика по кластеру, количество доступных IP-адресов, версия VMmanager и ченчлог продукта.
Есть список задач, разбитый по статусам: завершено, выполняется, в очереди на обработку, ошибка.
Можно посмотреть топ самых нагруженных узлов и отредактировать на них настройки оверселлинга.
Из дашборда можно перейти на список задач, кластер, ноду или виртуальную машину, чтобы приблизится к проблеме и детальнее оценить ситуацию.
Grafana
Благодаря интеграции с Grafana, можно гибко настроить визуализацию параметров в системе, статистику и анализировать инциденты.
Это работающий прямо из коробки контейнер с Grafana со всеми интеграциями, связями с базами данных и преднастроенным демо-дашбордом. Для осуществления мониторинга достаточно создать собственный дашборд, выбрать интересующую сущность, параметры и способ визуализации. Всё настраивается в простом графическом интерфейсе в пару кликов. Больше информации — в наше документации: как работать с Grafana в VMmanager.
Уведомления
Сервис уведомлений помогает вовремя реагировать на опасные инциденты. Например, если у провайдера перестанут выдаваться ВМ из биллинга, он сразу узнает об этом. А своевременные действия специалистов минимизируют негативное влияние на бизнес.
Сервис позволяет гибко задавать параметры пиков и событий. В нём вы можете настроить уведомления
- По параметрам: CPU, RAM, STORAGE, IOPS;
- По задачам в платформе: повреждение ВМ, недоступность сервера, ошибки в задачах на сервере, перезагрузка, ошибки создания ВМ и другие.
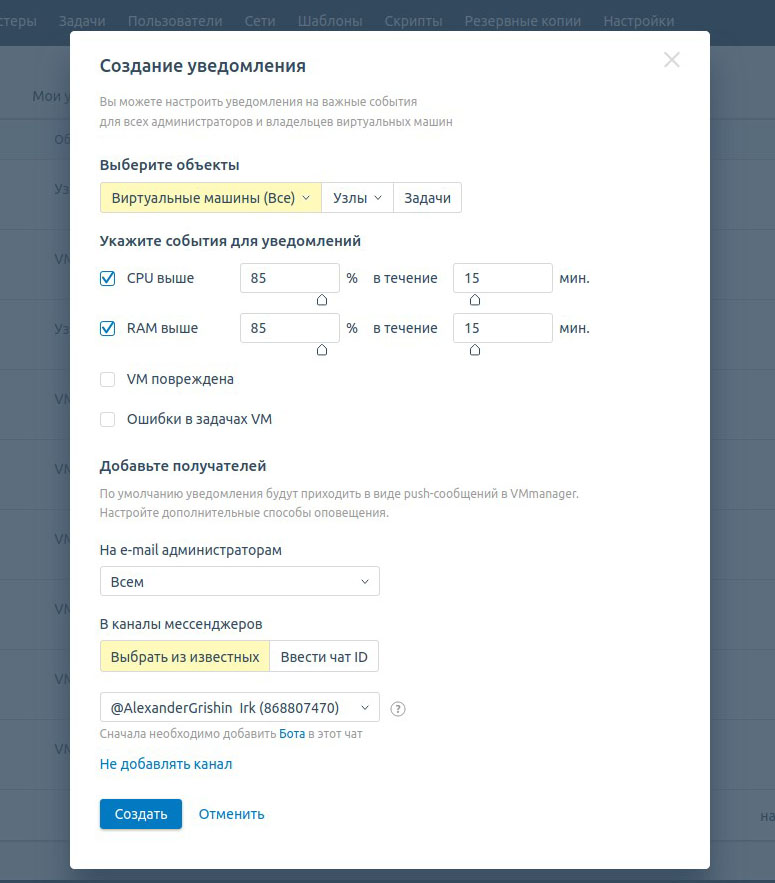
Уведомления можно получать в интерфейсе продукта, на почту и в Telegram. Подробнее об архитектуре сервиса рассказал Back-end разработчик Дмитрий Сыроватский в статье «Как мы написали сервис уведомлений».
Какие планы
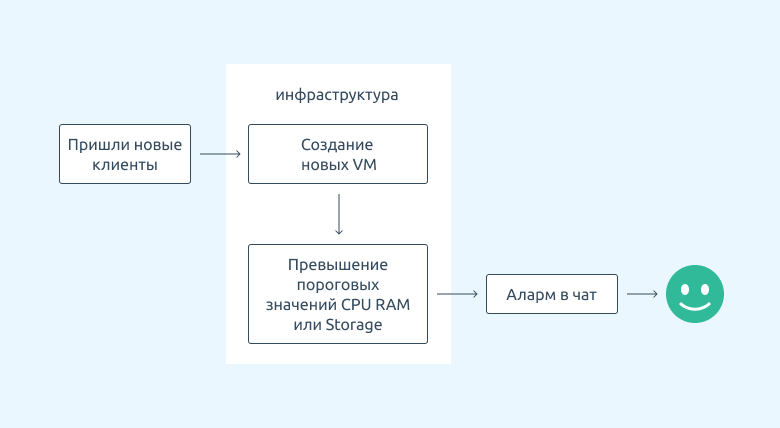
Сейчас в VMmanager готовая система собирает и визуализирует данные и сообщает о событиях в инфраструктуре на почту и в Telegram. В наших планах — добавить такие каналы связи как Slack и Mattermost. Но пока это одностороннее взаимодействие без обратной связи и возможности управления.
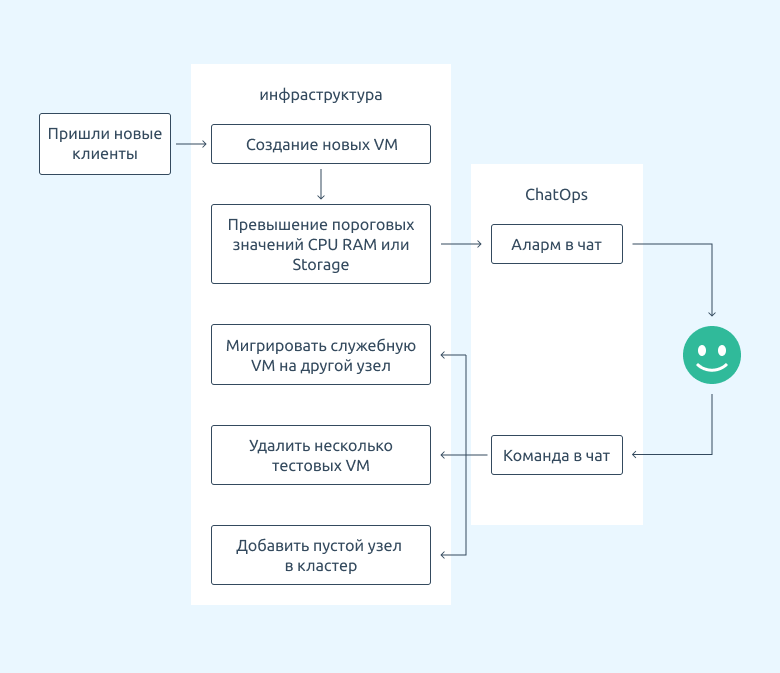
Что если добавить ChatOps систему, чтобы можно было управлять виртуальной инфраструктурой прямо из мессенджеров? Это даст возможность решать рабочие задачи даже в экстремальных ситуациях, когда нет полноценного доступа к платформе. Даже если системный администратор окажется в горах с одним мобильным телефоном, он сможет решить проблему с ушедшим в перезагрузку сервером — достаточно набрать соответствующую команду в мессенджере.
Так что же всё таки лучше для мониторинга: набор условно бесплатных инструментов с высоким порогом вхождения и долгим циклом внедрения? Или готовый коммерческий продукт с простым внедрением, удобным интерфейсом и грамотной технической поддержкой? Согласен, это спорный вопрос.
Однако мой опыт общения с представителями IT-индустрии показывает: бизнес намного чаще выбирает готовое коммерческое решение. Простой и понятный инструмент, готовый прямо сейчас приносить пользу компании.
А что насчет физического оборудования?
Рекомендуем использовать VMmanager в связке с платформой для управления физическим оборудованием DCImanager. Так вы получите мощный инструмент для мониторинга всей инфраструктуры и автоматизации технологических процессов.


